最近有个朋友找我帮忙处理一些音频文件,他目前主要遇到困难如下:
- 提取左声道
所有音频文件仅需要左声道即可,目前他们用的软件一次性只能处理 2000 个音频文件,但是他们目前一天需要处理的音频文件至少百万起步
- 识别没有声音的音频文件
目前需要人工将提取好的左声道音频文件丢进软件中过滤掉没有声音的音频文件
- 过滤无意义音频文件
目前需要人工过滤掉没有意义的音频文件,例如自动回复、语音助手等
听完他的描述后,我也想尝试一下,虽然自己以前没有接触过这些东西,但是大概的处理思路还是有的,借助 AI 问题不大,于是我叫他发我一些音频样本试试
# 音频声道提取
音频声道提取主要是用 FFmpeg 这个开源的多媒体音视频处理软件,配合脚本实现批量提取
#!/bin/bash | |
# 检查 FFmpeg 是否可用 | |
if ! command -v ffmpeg &> /dev/null; then | |
echo -e "\033[31m错误: FFmpeg 未安装或未添加到系统路径\033[0m" | |
echo -e "\033[33m请使用以下命令安装: sudo apt install ffmpeg\033[0m" | |
read -p "按回车键退出..." | |
exit 1 | |
fi | |
# 设置日期格式的目录 | |
folderName=$(date +"%Y%m%d") | |
mp3Path="/tmp/mp3" # 根据实际路径修改 | |
rootDir="$mp3Path/$folderName" | |
sourcePath="$rootDir/source" | |
leftChannelPath="$rootDir/leftChannel" | |
# 创建输出目录 | |
if [ -d "$rootDir" ]; then | |
echo "目录已存在: $rootDir" | |
else | |
mkdir -p "$sourcePath" | |
mkdir -p "$leftChannelPath" | |
echo "已创建目录: $rootDir" | |
fi | |
# 获取所有 MP3 文件 | |
mp3Files=() | |
while IFS= read -r -d $'\0' file; do | |
mp3Files+=("$file") | |
done < <(find "$mp3Path" -maxdepth 1 -type f -iname "*.mp3" -print0) | |
totalFiles=${#mp3Files[@]} | |
if [ "$totalFiles" -eq 0 ]; then | |
echo -e "\033[33m在 $mp3Path 中未找到MP3文件\033[0m" | |
read -p "按回车键退出..." | |
exit 1 | |
fi | |
echo -e "\033[36m开始处理 $totalFiles 个文件...\033[0m" | |
# 计数器 | |
processed=0 | |
successCount=0 | |
movedCount=0 | |
for file in "${mp3Files[@]}"; do | |
processed=$((processed + 1)) | |
percentage=$((processed * 100 / totalFiles)) | |
filename=$(basename -- "$file") | |
basename="${filename%.*}" | |
outputFile="$leftChannelPath/${basename}_LEFT.mp3" | |
# 显示进度 | |
echo -ne "\r\033[K处理中: $processed/$totalFiles ($percentage%) - $filename" | |
# 执行 FFmpeg 命令 | |
ffmpeg -hide_banner -ignore_unknown -i "$file" \ | |
-af "pan=mono|c0=FL" \ | |
-c:a libmp3lame -q:a 2 \ | |
"$outputFile" \ | |
-loglevel warning -y 2>/dev/null | |
if [ $? -eq 0 ]; then | |
echo -e "\r\033[K\033[32m[成功] $filename -> $(basename "$outputFile")\033[0m" | |
successCount=$((successCount + 1)) | |
# 移动源文件到 source 目录 | |
destination="$sourcePath/$filename" | |
mv -f "$file" "$destination" | |
if [ -f "$destination" ]; then | |
echo -e "\033[36m[移动] $filename -> source\033[0m" | |
movedCount=$((movedCount + 1)) | |
else | |
echo -e "\033[33m[警告] 移动失败: $filename\033[0m" | |
fi | |
else | |
echo -e "\r\033[K\033[31m[失败] $filename (错误代码: $?)\033[0m" | |
fi | |
done | |
echo -e "\n\033[36m所有文件处理完成!\033[0m" | |
echo -e "\033[36m输出目录: $leftChannelPath\033[0m" | |
echo -e "\033[36m源文件归档: $sourcePath\033[0m" | |
echo -e "\033[32m成功提取: $successCount/$totalFiles 个文件\033[0m" | |
echo -e "\033[36m成功移动: $movedCount/$totalFiles 个源文件\033[0m" | |
read -p "按回车键退出..." |
执行结果:

# 识别无声音频
识别没有声音的音频,主要是用 librosa 这个库,并且借助 matplotlib 生成波形图,以便于查看
import os | |
import argparse | |
import numpy as np | |
import librosa | |
import shutil | |
import csv | |
from tqdm import tqdm | |
import datetime | |
import matplotlib.pyplot as plt | |
import ssl | |
import urllib.request | |
# 禁用 SSL 证书验证 | |
ssl._create_default_https_context = ssl._create_unverified_context | |
def analyze_audio(audio_path, silence_threshold=0.001, max_peak=0.005): | |
""" | |
更可靠的静音检测方法:使用绝对振幅阈值 | |
""" | |
try: | |
# 读取音频文件 | |
y, sr = librosa.load(audio_path, sr=None, mono=True) | |
duration = librosa.get_duration(y=y, sr=sr) | |
# 计算整体 RMS 振幅(非分贝) | |
rms = np.sqrt(np.mean(y**2)) | |
# 计算最大峰值振幅 | |
peak = np.max(np.abs(y)) | |
# 计算静音帧比例 | |
frame_length = int(sr * 0.1) # 100ms 帧 | |
hop_length = frame_length // 2 | |
rms_frames = librosa.feature.rms(y=y, frame_length=frame_length, hop_length=hop_length)[0] | |
# 计算低于静音阈值的帧比例 | |
silent_frames = sum(1 for frame_rms in rms_frames if frame_rms < silence_threshold) | |
silent_ratio = silent_frames / len(rms_frames) if len(rms_frames) > 0 else 1.0 | |
# 判定是否为静音文件 | |
is_silent = False | |
# 条件 1: 整体 RMS 振幅非常低 | |
if rms < silence_threshold * 0.5: | |
is_silent = True | |
# 条件 2: 最大峰值振幅非常低 | |
elif peak < max_peak * 0.5: | |
is_silent = True | |
# 条件 3: 静音帧比例非常高 | |
elif silent_ratio > 0.95 and rms < silence_threshold: | |
is_silent = True | |
# 生成波形图 | |
plt.figure(figsize=(12, 4)) | |
time_axis = np.linspace(0, duration, len(y)) | |
plt.plot(time_axis, y, alpha=0.6, label='波形') | |
# 添加阈值线 | |
plt.axhline(y=silence_threshold, color='green', linestyle='--', label=f'静音阈值 ({silence_threshold})') | |
plt.axhline(y=-silence_threshold, color='green', linestyle='--') | |
plt.axhline(y=max_peak, color='red', linestyle='--', label=f'峰值阈值 ({max_peak})') | |
plt.axhline(y=-max_peak, color='red', linestyle='--') | |
plt.title(f"音频分析: {os.path.basename(audio_path)}\n状态: {'静音' if is_silent else '有效'}") | |
plt.xlabel("时间 (秒)") | |
plt.ylabel("振幅") | |
plt.legend(loc='upper right') | |
plt.grid(True, alpha=0.3) | |
# 保存波形图 | |
waveform_path = os.path.splitext(audio_path)[0] + "_analysis.png" | |
plt.savefig(waveform_path, dpi=100, bbox_inches='tight') | |
plt.close() | |
return { | |
"filename": os.path.basename(audio_path), | |
"filepath": audio_path, | |
"duration": duration, | |
"rms": float(rms), | |
"peak": float(peak), | |
"silent_ratio": float(silent_ratio), | |
"waveform_path": waveform_path, | |
"is_silent": is_silent, | |
"status": "SILENT" if is_silent else "ACTIVE", | |
"error": None | |
} | |
except Exception as e: | |
return { | |
"filename": os.path.basename(audio_path), | |
"filepath": audio_path, | |
"duration": 0, | |
"rms": 0, | |
"peak": 0, | |
"silent_ratio": 0, | |
"waveform_path": "", | |
"is_silent": False, | |
"status": f"ERROR: {str(e)}", | |
"error": str(e) | |
} | |
def detect_silent_files(input_dir, output_dir, silence_threshold=0.001, max_peak=0.005): | |
""" | |
可靠的静音检测与分类 | |
""" | |
# 创建输出目录 | |
silent_dir = os.path.join(output_dir, "silent") | |
active_dir = os.path.join(output_dir, "active") | |
review_dir = os.path.join(output_dir, "review") | |
os.makedirs(silent_dir, exist_ok=True) | |
os.makedirs(active_dir, exist_ok=True) | |
os.makedirs(review_dir, exist_ok=True) | |
# 获取所有音频文件 | |
audio_files = [] | |
for file in os.listdir(input_dir): | |
if file.lower().endswith(('.mp3', '.wav', '.flac', '.ogg', '.m4a')): | |
audio_files.append(os.path.join(input_dir, file)) | |
print(f"在目录 {input_dir} 中找到 {len(audio_files)} 个音频文件") | |
print(f"使用参数: 静音阈值={silence_threshold}, 峰值阈值={max_peak}") | |
# 创建报告文件 | |
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S") | |
report_path = os.path.join(output_dir, f"静音检测报告_{timestamp}.csv") | |
# 打开 CSV 报告文件 | |
with open(report_path, 'w', newline='', encoding='utf-8') as csvfile: | |
fieldnames = ['文件名', '原始路径', '时长(秒)', 'RMS振幅', '峰值振幅', | |
'静音帧比例(%)', '状态', '目标路径', '波形图路径'] | |
writer = csv.DictWriter(csvfile, fieldnames=fieldnames) | |
writer.writeheader() | |
# 处理每个文件 | |
silent_count = 0 | |
active_count = 0 | |
review_count = 0 | |
for file_path in tqdm(audio_files, desc="分析音频文件"): | |
result = analyze_audio(file_path, silence_threshold, max_peak) | |
dest_path = "" | |
try: | |
if result["status"] == "SILENT": | |
# 移动静音文件 | |
dest_path = os.path.join(silent_dir, os.path.basename(file_path)) | |
shutil.move(file_path, dest_path) | |
silent_count += 1 | |
elif result["status"] == "ACTIVE": | |
# 移动非静音文件 | |
dest_path = os.path.join(active_dir, os.path.basename(file_path)) | |
shutil.move(file_path, dest_path) | |
active_count += 1 | |
else: | |
# 错误文件移动到 review 目录 | |
dest_path = os.path.join(review_dir, os.path.basename(file_path)) | |
shutil.move(file_path, dest_path) | |
review_count += 1 | |
except Exception as e: | |
# 错误文件移动到 review 目录 | |
dest_path = os.path.join(review_dir, os.path.basename(file_path)) | |
shutil.move(file_path, dest_path) | |
result["error"] = f"移动失败: {str(e)}" | |
result["status"] = f"ERROR: {str(e)}" | |
review_count += 1 | |
# 写入报告行 | |
writer.writerow({ | |
'文件名': result["filename"], | |
'原始路径': result["filepath"], | |
'时长(秒)': f"{result['duration']:.2f}", | |
'RMS振幅': f"{result['rms']:.6f}", | |
'峰值振幅': f"{result['peak']:.6f}", | |
'静音帧比例(%)': f"{result['silent_ratio']*100:.1f}", | |
'状态': result["status"], | |
'目标路径': dest_path, | |
'波形图路径': result["waveform_path"] | |
}) | |
# 生成统计报告 | |
total_files = len(audio_files) | |
summary = f"\n静音检测完成!\n" \ | |
f"总文件数: {total_files}\n" \ | |
f"静音文件: {silent_count} ({silent_count/total_files*100:.1f}%)\n" \ | |
f"有效音频: {active_count} ({active_count/total_files*100:.1f}%)\n" \ | |
f"需要复查: {review_count} ({review_count/total_files*100:.1f}%)\n" \ | |
f"\n文件已分类移动到:\n" \ | |
f"静音文件: {silent_dir}\n" \ | |
f"有效音频: {active_dir}\n" \ | |
f"需要复查: {review_dir}\n" \ | |
f"\n详细报告已保存到: {report_path}" | |
# 保存统计报告 | |
summary_path = os.path.join(output_dir, f"统计报告_{timestamp}.txt") | |
with open(summary_path, "w", encoding="utf-8") as f: | |
f.write(summary) | |
print(summary) | |
print(f"统计报告已保存到: {summary_path}") | |
if __name__ == "__main__": | |
parser = argparse.ArgumentParser(description="可靠静音检测工具 (基于振幅阈值)") | |
parser.add_argument("input_dir", help="包含音频文件的输入目录") | |
parser.add_argument("output_dir", help="保存分类结果的输出目录") | |
parser.add_argument("--silence_threshold", type=float, default=0.001, | |
help="静音检测阈值 (默认: 0.001)") | |
parser.add_argument("--max_peak", type=float, default=0.005, | |
help="最大峰值阈值 (默认: 0.005)") | |
args = parser.parse_args() | |
# 运行检测 | |
detect_silent_files( | |
input_dir=args.input_dir, | |
output_dir=args.output_dir, | |
silence_threshold=args.silence_threshold, | |
max_peak=args.max_peak | |
) |
执行结果:
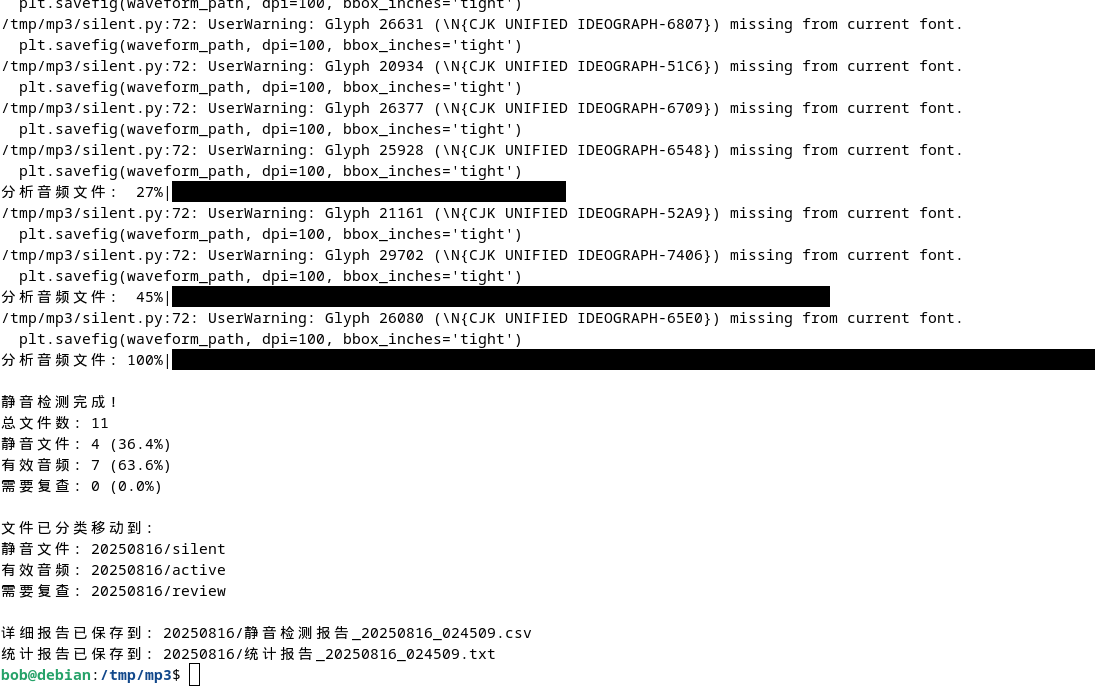
# 识别助手音频
识别语音助手的话,我第一时间想到的是将语音转换成文本文件,然后再通过关键字匹配,这里主要用到的是
PaddleSpeech 这个开源项目,代码如下:
import os | |
import sys | |
import glob | |
import shutil | |
import tempfile | |
from concurrent.futures import ThreadPoolExecutor, as_completed | |
from pydub import AudioSegment | |
from paddlespeech.cli.asr.infer import ASRExecutor | |
# 定义 AI 语音常见关键词 | |
AI_KEYWORDS = [ | |
"助手", "无法接通", "留言", "智能", "助理", "您拨打的", | |
"通话中","无法接听", "挂断" | |
] | |
# 配置参数 | |
DEST_DIR = "/home/bob/AI_Voice" # 默认 AI 语音存储目录 | |
MAX_WORKERS = 4 # 线程池大小,根据 CPU 核心数调整 | |
def convert_mp3_to_wav(mp3_path): | |
"""将MP3转换为临时WAV文件""" | |
temp_file = tempfile.NamedTemporaryFile(suffix=".wav", delete=False) | |
temp_path = temp_file.name | |
temp_file.close() | |
audio = AudioSegment.from_mp3(mp3_path) | |
audio = audio.set_frame_rate(16000).set_channels(1) | |
audio.export(temp_path, format="wav") | |
return temp_path | |
def detect_ai_voice_by_keywords(mp3_path, asr_executor): | |
"""使用PaddleSpeech API识别语音并检测AI关键词""" | |
wav_path = convert_mp3_to_wav(mp3_path) | |
try: | |
text = asr_executor(audio_file=wav_path, lang='zh') | |
print(f"识别的文本: {text}") | |
for keyword in AI_KEYWORDS: | |
if keyword in text: | |
return True, text | |
return False, text | |
except Exception as e: | |
print(f"处理出错: {str(e)}") | |
return False, "" | |
finally: | |
if os.path.exists(wav_path): | |
os.unlink(wav_path) | |
def move_file(src_path, dest_dir, text): | |
"""移动文件到目标目录并添加元数据""" | |
os.makedirs(dest_dir, exist_ok=True) | |
filename = os.path.basename(src_path) | |
dest_path = os.path.join(dest_dir, filename) | |
try: | |
shutil.move(src_path, dest_path) | |
print(f"已移动文件到: {dest_path}") | |
return True | |
except Exception as e: | |
print(f"移动文件失败: {str(e)}") | |
return False | |
def process_file(mp3_file, dest_dir, asr_executor): | |
"""处理单个文件并移动AI语音文件""" | |
print(f"\n处理文件: {os.path.basename(mp3_file)}") | |
is_ai, text = detect_ai_voice_by_keywords(mp3_file, asr_executor) | |
if is_ai: | |
print(" >> 检测到AI语音") | |
if move_file(mp3_file, dest_dir, text): | |
return True, "检测到AI语音并已移动" | |
else: | |
return False, "检测到AI语音但移动失败" | |
else: | |
print(" >> 未检测到AI语音") | |
return False, "未检测到AI语音" | |
def process_directory(source_path, dest_dir): | |
"""多线程处理目录下的所有MP3文件""" | |
mp3_files = glob.glob(os.path.join(source_path, "*.mp3")) | |
if not mp3_files: | |
print(f"目录 {source_path} 中没有找到MP3文件") | |
return 0, 0 | |
print(f"开始处理目录: {source_path}") | |
print(f"找到 {len(mp3_files)} 个MP3文件") | |
# 统计结果 | |
ai_count = 0 | |
moved_count = 0 | |
# 创建线程池和 ASRExecutor 实例 | |
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: | |
# 每个线程使用自己的 ASRExecutor 实例 | |
futures = [] | |
for mp3_file in mp3_files: | |
# 为每个任务创建新的 ASRExecutor 实例 | |
asr_executor = ASRExecutor() | |
future = executor.submit(process_file, mp3_file, dest_dir, asr_executor) | |
futures.append(future) | |
# 收集结果 | |
for future in as_completed(futures): | |
moved, message = future.result() | |
if moved: | |
ai_count += 1 | |
moved_count += 1 | |
elif "检测到AI语音" in message: | |
ai_count += 1 | |
return ai_count, moved_count | |
def main(): | |
if len(sys.argv) < 2: | |
print("用法: python lessvoice.py <源文件或目录路径> [目标目录]") | |
print(f"示例: python lessvoice.py /home/bob/Documents/mp3/ {DEST_DIR}") | |
sys.exit(1) | |
source_path = sys.argv[1] | |
dest_dir = sys.argv[2] if len(sys.argv) > 2 else DEST_DIR | |
os.makedirs(dest_dir, exist_ok=True) | |
print(f"AI语音将保存到: {dest_dir}") | |
if os.path.isfile(source_path): | |
# 处理单个文件 | |
asr_executor = ASRExecutor() | |
result, message = process_file(source_path, dest_dir, asr_executor) | |
print(f"{source_path}: {message}") | |
elif os.path.isdir(source_path): | |
# 多线程处理目录 | |
ai_count, moved_count = process_directory(source_path, dest_dir) | |
print(f"\n处理完成! 共发现 {ai_count} 个有效语音文件,成功识别并移动 {moved_count} 个AI音频文件到 {dest_dir}") | |
else: | |
print(f"路径不存在或无效: {source_path}") | |
if __name__ == "__main__": | |
os.environ["PIP_BREAK_SYSTEM_PACKAGES"] = "1" | |
main() |
执行结果:

从转换的文本结果来看,正确率应该在 50% 左右,不过可以通过关键字识别,问题不大
由于朋友提供的样本数量过少,我也只能做到从他给我的 11 个样本中按照他提出的要求进行测试,目前三个脚本执行的结果跟预期一样,应该可以满足他的要求